Algoritma Machine Learning Berperan Dalam
Tantangan dalam Machine Learning
Kualitas data yang buruk dapat menyebabkan model machine learning tidak akurat. Data yang lengkap dan bersih sangat penting untuk hasil yang optimal.
Mulai Belajar Menjadi Data Scientist dari Sekarang!
Tahukah kalian bahwa data scientist kini sangat banyak diminati oleh berbagai kalangan. Data scientist merupakan profesi terseksi di abad ini serta gaji dan jenjang karirnya pun cukup menjanjikan. Jadi, Untuk mengetahui lebih lanjut terkait data scientist kita dapat mempelajarinya di DQLab lohh. Caranya sangat mudah, yaitu cukup signup di DQLab dan nikmati momen belajar gratis bersama DQLab dengan mengakses module gratis dari R, Python atau SQL!
Penulis : Latifah Uswatun Khasanah
Editor : Annissa Widya Davita
Algoritma machine learning adalah metode dimana sistem artificial intelligence mengerjakan tugasnya secara otomatis. Umumnya algoritma machine learning ini digunakan untuk memprediksi nilai output dari input yang diberikan. Dua proses utama dari algoritma machine learning adalah klasifikasi dan regresi.
Algoritma machine learning sendiri dibagi menjadi dua, yaitu supervised dan unsupervised learning. Supervised learning membutuhkan data input dan data output yang diinginkan dan digunakan untuk membuat pelabelan, sedangkan algoritma unsupervised learning bekerja dengan data yang tidak diklasifikasikan atau tidak diberi label.
Contoh algoritma unsupervised learning adalah pengelompokan atau clustering data yang tidak difilter berdasarkan persamaan dan perbedaan. Pada artikel kali ini, kita akan membahas algoritma supervised learning, yaitu algoritma klasifikasi atau classification.
Terkadang sulit memutuskan algoritma machine learning mana yang paling baik untuk klasifikasi diantara banyaknya pilihan dan jenis algoritma klasifikasi yang ada. Namun, ada algoritma klasifikasi machine learning yang paling baik digunakan dalam masalah atau situasi tertentu.
Algoritma klasifikasi ini digunakan untuk klasifikasi teks, analisis sentimen, deteksi spam, deteksi penipuan, segmentasi pelanggan, dan klasifikasi gambar. Pilihan algoritma yang sesuai bergantung pada kumpulan data dan tujuan yang akan dicapai.
Lalu apa saja algoritma klasifikasi terbaik tersebut? Yuk simak artikel kali ini hingga akhir!
Source: Thanmai Chandaka
Decision tree membangun model klasifikasi dan regresi dalam bentuk struktur pohon. Algoritma ini menguraikan kumpulan data menjadi himpunan bagian yang lebih kecil dan menghubungkannya menjadi pohon keputusan yang terkait. Tujuan utama dari algoritma decision tree adalah untuk membangun model pelatihan yang digunakan untuk memprediksi nilai variabel target dengan mempelajari aturan keputusan. Aturan ini disimpulkan dari data training yang sebelumnya telah diinput. Keuntungan algoritma ini adalah mudah dimengerti, mudah menghasilkan aturan, tidak mengandung hiper-parameter, dan model decision tree yang kompleks dapat disederhanakan secara signifikan dengan visualisasinya.
Decision tree membangun model klasifikasi dan regresi dalam bentuk struktur pohon. Algoritma ini menguraikan kumpulan data menjadi himpunan bagian yang lebih kecil dan menghubungkannya menjadi pohon keputusan yang terkait.
Tujuan utama dari algoritma decision tree adalah untuk membangun model pelatihan yang digunakan untuk memprediksi nilai variabel target dengan mempelajari aturan keputusan. Aturan ini disimpulkan dari data training yang sebelumnya telah diinput.
Keuntungan algoritma ini adalah mudah dimengerti, mudah menghasilkan aturan, tidak mengandung hiper-parameter, dan model decision tree yang kompleks dapat disederhanakan secara signifikan dengan visualisasinya.
Baca juga : Yuk Kenali Macam-Macam Algoritma Machine Learning!
Unsupervised Learning
Unsupervised learning adalah kebalikan dari supervised learning. Di sini, model dilatih dengan data yang tidak diberi label. Bayangkan kamu masuk ke dalam ruangan gelap dan harus mencari tahu tata letaknya sendiri.
Etika dan Privasi
Penggunaan machine learning menimbulkan isu etika dan privasi. Misalnya, bagaimana data dikumpulkan dan digunakan tanpa mengganggu privasi individu?
Reinforcement Learning
Reinforcement learning adalah metode di mana agen belajar melalui trial and error, mendapatkan hadiah atau hukuman berdasarkan tindakannya. Seperti anjing yang dilatih untuk duduk dengan imbalan biskuit.
Random Forest Classifier
Algoritma Random Forest Classifier merupakan salah satu algoritma klasifikasi machine learning yang paling populer. Seperti namanya, algoritma ini bekerja dengan cara membuat hutan pohon secara acak. Semakin banyak pohon yang dibuat, maka hasilnya akan semakin akurat.
Dasar dari algoritma random forest adalah algoritma decision tree. Keuntungan dari algoritma ini adalah dapat digunakan u8ntuk rekayasa fitur seperti mengidentifikasi fitur yang paling penting diantara semua fitur yang tersedia dalam dataset training, bekerja sangat baik pada database berukuran besar, sangat fleksibel, dan memiliki akurasi yang tinggi.
4. Support Vector Machine
Support Vector Machine atau biasa dikenal dengan algoritma SVM adalah algoritma machine learning yang digunakan untuk masalah klasifikasi atau regresi. Namun, aplikasi yang paling sering digunakan adalah masalah klasifikasi.
Algoritma SVM banyak digunakan untuk mengklasifikasikan dokumen teknis misalnya spam filtering, mengkategorikan artikel berita berdasarkan topik, dan lain sebagainya. Keuntungan algoritma ini adalah cepat, efektif untuk ruang dimensi tinggi, akurasi yang bagus, powerful dan fleksibel, dan dapat digunakan di banyak aplikasi.
Bcaa juga : Bootcamp Machine Learning and AI for Beginner
Di era big data, machine learning merupakan salah satu teknologi yang banyak dicari. Hal ini menyebabkan meningkatnya minat belajar algoritma machine learning. Karena sebagian besar menggunakan data berukuran besar, maka tools yang digunakan pun tidak sembarangan dan perlu keahlian untuk mengaplikasikan tools tersebut. Ingin belajar machine learning beserta tools-nya? Yuk bergabung bersama DQLab!
DQLab adalah platform edukasi pertama yang mengintegrasi fitur ChatGPT yang memudahkan beginner untuk mengakses informasi mengenai data science secara lebih mendalam.
DQLab juga menggunakan metode HERO yaitu Hands-On, Experiential Learning & Outcome-based, yang dirancang ramah untuk pemula. Jadi sangat cocok untuk kamu yang belum mengenal data science sama sekali. Untuk bisa merasakan pengalaman belajar yang praktis dan aplikatif, yuk sign up sekarang di DQLab.id atau ikuti Bootcamp Machine Learning and AI for Beginner berikut untuk informasi lebih lengkapnya!
Penulis: Galuh Nurvinda K
Ket. foto: Ilustrasi - Machine learning. Shutterstock.
Algoritma dalam machine learning adalah sekumpulan aturan yang digunakan oleh sistem machine learning untuk mengambil keputusan atau membuat prediksi. Algoritma dalam machine learning dapat dibagi menjadi dua kategori yaitu supervised learning dan unsupervised learning. Supervised learning adalah algoritma yang digunakan untuk membuat prediksi berdasarkan data latihan yang sudah ditandai dengan label atau target yang diinginkan. Sedangkan unsupervised learning adalah algoritma yang digunakan untuk menemukan struktur atau pola dalam data yang tidak dikenal sebelumnya. Ada berbagai jenis algoritma machine learning yang digunakan dalam berbagai aplikasi, seperti algoritma regresi, klasifikasi, clustering, dan deep learning.
Algoritma adalah sekumpulan aturan yang digunakan untuk menyelesaikan suatu masalah atau untuk mencapai tujuan tertentu. Algoritma dapat didefinisikan sebagai serangkaian langkah-langkah yang harus diikuti secara sistematis dan logis untuk menyelesaikan masalah atau mencapai tujuan tertentu. Algoritma dapat digambarkan dalam bentuk flowchart, pseudocode, atau bahasa pemrograman. Algoritma dapat digunakan dalam berbagai bidang, seperti matematika, komputer, pengambilan keputusan, dan lainnya. Dalam bidang komputer, algoritma digunakan dalam pemrograman untuk menyelesaikan masalah-masalah yang kompleks.
Baca Juga: Pentingnya Sentiment Analysis dalam Annual Report
Naive Bayes Classifier
Source: Koushiki Dasgupta Chauduri
Naive bayes classifier merupakan algoritma klasifikasi yang sangat sederhana berdasarkan apa yang disebut pada teorema bayesian. Algoritma ini memiliki satu sifat umum, yaitu setiap data diklasifikasikan tidak bergantung pada fitur lain yang terikat pada kelas atau biasa disebut dengan independen. Artinya, satu data tidak berdampak pada data yang lain.
Meskipun algoritma ini merupakan algoritma yang tergolong sederhana, namun naive bayes dapat mengalahkan beberapa metode klasifikasi yang lebih canggih. Algoritma ini biasa digunakan untuk deteksi spam dan klasifikasi dokumen teks.
Kelebihan algoritma ini adalah sederhana dan mudah diterapkan, tidak sensitif terhadap fitur yang tidak relevan, cepat, hanya membutuhkan sedikit data training, dan dapat digunakan untuk masalah klasifikasi multi-class dan biner.
Reinforcement Learning
Reinforcement learning adalah jenis machine learning di mana model belajar melalui interaksi dengan lingkungan.
Tujuan dari reinforcement learning adalah untuk memaksimalkan reward atau penghargaan yang diberikan oleh lingkungan. Contoh dari reinforcement learning adalah robotika dan game.
Suatu perusahaan ingin mengembangkan robot yang dapat berjalan dan menghindari rintangan di sekitarnya.
Tujuan dari reinforcement learning adalah membuat model yang dapat memaksimalkan reward yang diberikan saat robot berhasil melewati rintangan tanpa bertabrakan.
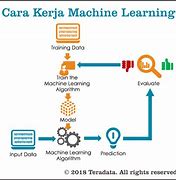
Algoritma Machine Learning
Algoritma machine learning dapat dikategorikan ke dalam tiga jenis:
Supervised learning adalah jenis machine learning di mana data yang digunakan untuk melatih model memiliki label atau jawaban yang benar.
Tujuan dari supervised learning adalah untuk membuat model yang dapat memprediksi label dari data yang tidak memiliki label.
Kegunaan dari supervised learning adalah untuk klasifikasi, regresi, dan deteksi anomali.
Suatu perusahaan ingin memprediksi apakah pelanggan akan membeli produk tertentu atau tidak. Data yang tersedia adalah riwayat pembelian pelanggan, riwayat aktivitas di website, usia, jenis kelamin, dan pendapatan.
Data tersebut diberi label "ya" atau "tidak" berdasarkan apakah pelanggan membeli produk tersebut atau tidak.
Tujuan dari supervised learning adalah membuat model yang dapat memprediksi apakah pelanggan akan membeli produk tersebut atau tidak berdasarkan data yang tersedia.
Apa Itu Algoritma Machine Learning?
Algoritma machine learning adalah metode yang digunakan komputer untuk mengenali pola dan membuat keputusan berdasarkan data yang ada. Nah, algoritma ini seperti juru sihir modern yang bisa meramalkan masa depan (tapi tanpa bola kristal dan jubah). Dari klasifikasi email spam hingga prediksi saham, semua bisa dilakukan dengan sihir algoritma ini.



